Introducción a git
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
📖 git-scm
Git es un software de control de versiones diseñado por Linus Torvalds, pensando en la eficiencia, la confiabilidad y compatibilidad del mantenimiento de versiones de aplicaciones cuando estas tienen un gran número de archivos de código fuente. Su propósito es llevar registro de los cambios en archivos de computadora incluyendo coordinar el trabajo que varias personas realizan sobre archivos compartidos en un repositorio de código.
Historia
El kernel de Linux es un proyecto de software de código abierto con un alcance bastante amplio. Durante la mayor parte del mantenimiento del kernel de Linux (1991-2002), los cambios en el software se realizaban a través de parches y archivos. En el 2002, el proyecto del kernel de Linux empezó a usar un DVCS propietario llamado BitKeeper.
En el 2005, la relación entre la comunidad que desarrollaba el kernel de Linux y la compañía que desarrollaba BitKeeper se vino abajo y la herramienta dejó de ser ofrecida de manera gratuita. Esto impulsó a la comunidad de desarrollo de Linux (y en particular a Linus Torvalds, el creador de Linux) a desarrollar su propia herramienta basada en algunas de las lecciones que aprendieron mientras usaban BitKeeper. Algunos de los objetivos del nuevo sistema fueron los siguientes:
- Velocidad
- Diseño sencillo
- Gran soporte para desarrollo no lineal (miles de ramas paralelas)
- Completamente distribuido
- Capaz de manejar grandes proyectos (como el kernel de Linux) eficientemente (velocidad y cantidad de datos)
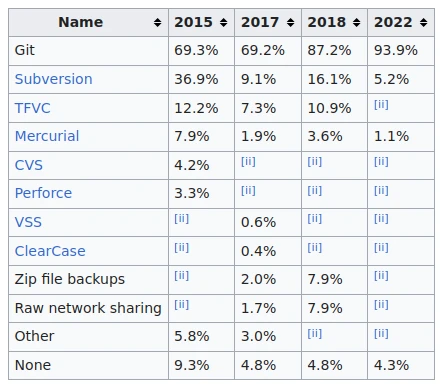
En esta tabla podemos ver la adopción de Git en los últimos años:
Version control
Un control de versiones es un sistema que registra los cambios realizados en un archivo o conjunto de archivos a lo largo del tiempo, de modo que puedas recuperar versiones específicas más adelante.
Fundamentos de Git
Copias instantáneas
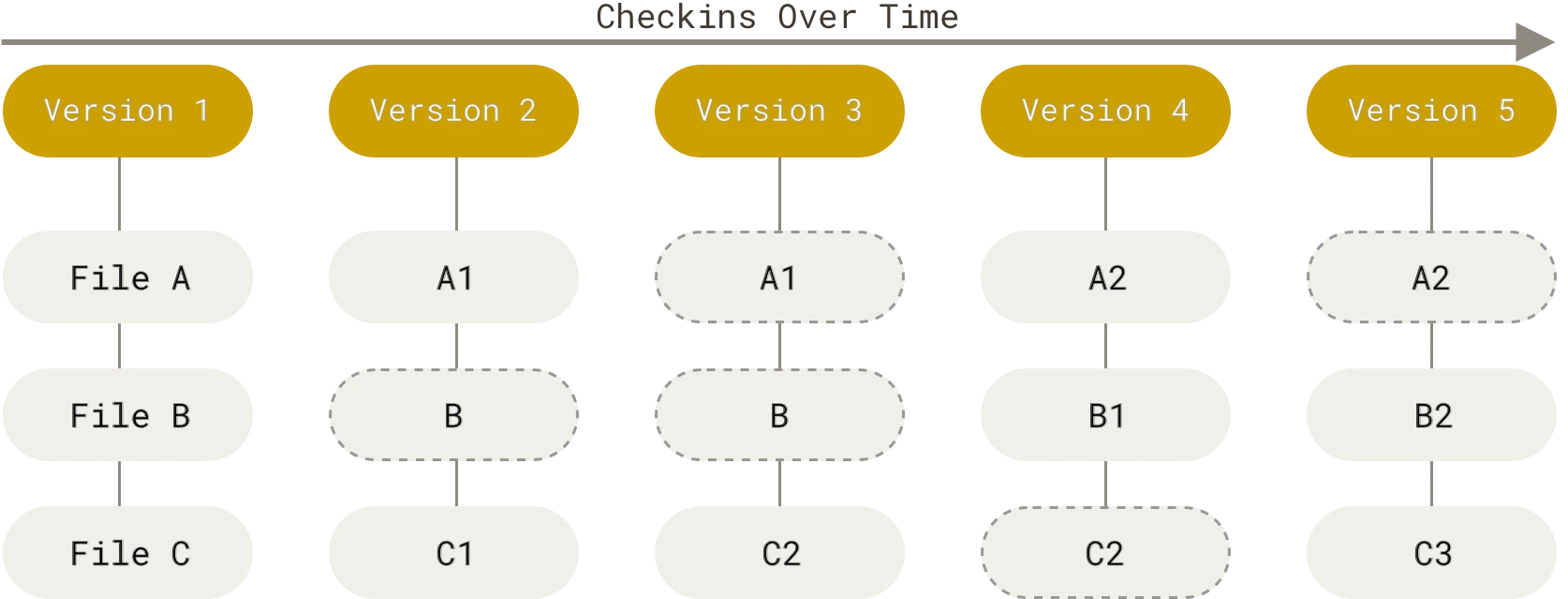
Git maneja sus datos como un conjunto de copias instantáneas de un sistema de archivos miniatura. Cada vez que confirmas un cambio, o guardas el estado de tu proyecto en Git, él básicamente toma una foto del aspecto de todos tus archivos en ese momento y guarda una referencia a esa copia instantánea. Para ser eficiente, si los archivos no se han modificado Git no almacena el archivo de nuevo, sino un enlace al archivo anterior idéntico que ya tiene almacenado. Git maneja sus datos como una secuencia de copias instantáneas.
Casi todas las operaciones son locales
La mayoría de las operaciones en Git sólo necesitan archivos y recursos locales para funcionar. Por lo general no se necesita información de ningún otro computador de tu red.
Esto también significa que hay muy poco que no puedes hacer si estás desconectado o sin VPN. Si te subes a un avión o a un tren y quieres trabajar un poco, puedes confirmar tus cambios felizmente hasta que consigas una conexión de red para subirlos
Git tiene integridad
Todo en Git es verificado mediante una suma de comprobación (checksum en inglés) antes de ser almacenado, y es identificado a partir de ese momento mediante dicha suma. Esto significa que es imposible cambiar los contenidos de cualquier archivo o directorio sin que Git lo sepa. Esta funcionalidad está integrada en Git al más bajo nivel y es parte integral de su filosofía. No puedes perder información durante su transmisión o sufrir corrupción de archivos sin que Git sea capaz de detectarlo.
Git generalmente solo añade información
Cuando realizas acciones en Git, casi todas ellas sólo añaden información a la base de datos de Git. Es muy difícil conseguir que el sistema haga algo que no se pueda enmendar, o que de algún modo borre información. Como en cualquier VCS, puedes perder o estropear cambios que no has confirmado todavía. Pero después de confirmar una copia instantánea en Git es muy difícil perderla, especialmente si envías tu base de datos a otro repositorio con regularidad.
Los Tres Estados
Git tiene tres estados principales en los que se pueden encontrar tus archivos: confirmado (committed), modificado (modified), y preparado (staged).
-
Confirmado: (commited) significa que los datos están almacenados de manera segura en tu base de datos local.
-
Modificado: significa que has modificado el archivo pero todavía no lo has confirmado a tu base de datos.
-
Preparado: significa que has marcado un archivo modificado en su versión actual para que vaya en tu próxima confirmación.
Esto nos lleva a las tres secciones principales de un proyecto de Git: El directorio de Git (Git directory), el directorio de trabajo (working directory), y el área de preparación (staging area).
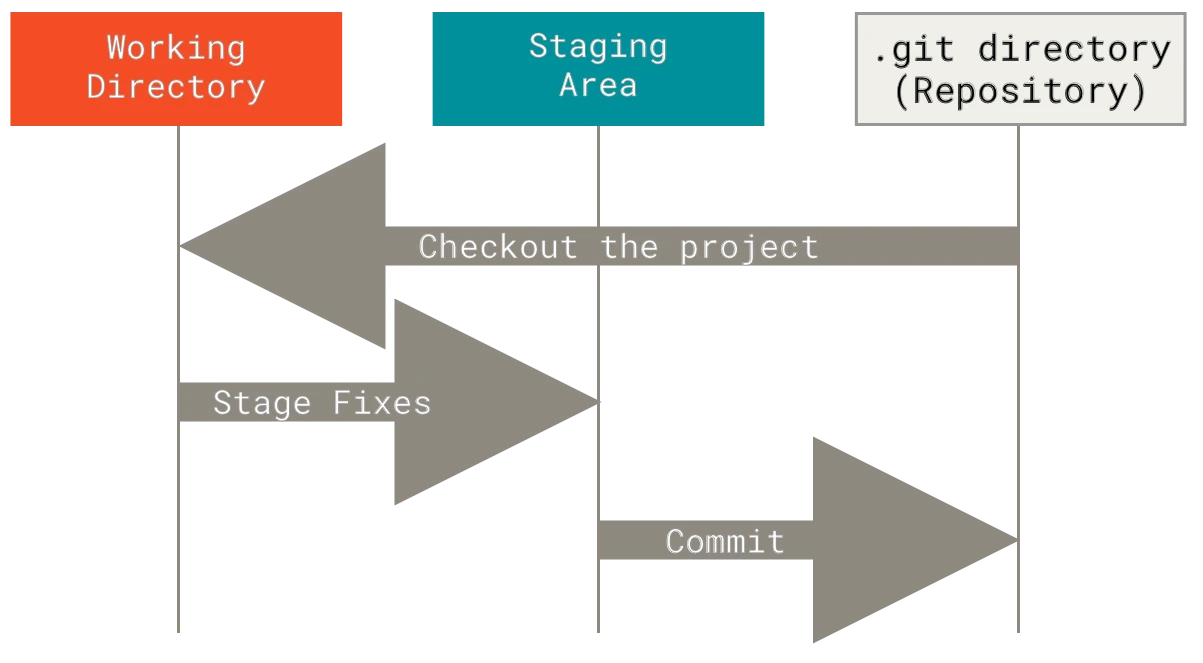
El flujo de trabajo básico en Git es algo así:
- Modificas una serie de archivos en tu directorio de trabajo.
- Preparas (stage) los archivos, añadiéndolos a tu área de preparación.
- Confirmas (commit) los cambios, lo que toma los archivos tal y como están en el área de preparación y almacena esa copia instantánea de manera permanente en tu directorio de Git.
Para agregar los cambios hechos en un archivo al área de stage podemos utilizar el comando:
git add nombre_archivo
Utilizando la opcion -p, podemos seleccionar interactivamente que cambios queremos agregar al area de preparación (staging area).
Por ejemplo: git add -p nombre_archivo
y una vez que tengamos todos los cambios listos y agregados utilizamos el comando:
git commit -m "Mensaje describiendo los cambios"
el modificador -m nos permite poner un título o mensaje a nuestros cambios, si no lo incluimos en la línea de comando, al hacer el commit git abrirá un editor de texto donde podemos ponerlo.
Ignorar Archivos
A veces, tendrás algún tipo de archivo que no quieres que Git añada automáticamente o más aun, que ni siquiera quieras que aparezca como no rastreado. Este suele ser el caso de archivos generados automáticamente como trazas o archivos creados por tu sistema de compilación. En estos casos, puedes crear un archivo llamado .gitignore que liste patrones a considerar.
Este es un ejemplo de un archivo .gitignore:
*.a
build/
secret
La primera línea solicita ignorar todos los archivos que terminen en .a, la segunda todo el directorio build y su contenido y la tercera el archivo llamado secret.
Creando repositorios
Inicializando un repositorio en un directorio existente
Si estás empezando a seguir un proyecto existente en Git, debes ir al directorio del proyecto y usar el siguiente comando:
$ git init
Esto crea un subdirectorio nuevo, llamado .git (oculto), el cual contiene todos los archivos necesarios del repositorio – un esqueleto de un repositorio de Git. Todavía no hay nada en tu proyecto que esté bajo seguimiento. Hace falta preparar y confirmar los archivos que quieres agregar a tu nuevo repositorio con:
git add archivo1
git add archivoN
git commit -m "Agregando archivos de la version inicial"
Clonando un repositorio existente
Si deseas obtener una copia de un repositorio Git existente — por ejemplo, un proyecto en el que te gustaría contribuir — el comando que necesitas es git clone.
Si ejecutas el siguiente comando:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
Tendrás una copia local del kernel de linux en su versión estable lista para agregar cambios.
Cuando quieras publicar tus cambios en el repositorio remoto debes seguir el procedimiento normal de agregarlos al stage, hacer un commit y por último empujarlos al repositorio remoto:
git add nombre_archivo
git commit -m "Descripción de los cambios"
git push
Para actualizar tu copia del repositorio con los cambios que otros usuarios hayan empujado al repositorio remoto puedes utilizar el comando:
git pull
La herramienta principal para determinar qué archivos están en qué estado es el comando git status.
Si ejecutas este comando inmediatamente después de clonar un repositorio, deberías ver algo como esto:
$ git status
On branch master
nothing to commit, working directory clean
Remotos

Para poder colaborar en cualquier proyecto Git, necesitas saber cómo gestionar repositorios remotos. Los repositorios remotos son versiones de tu proyecto que están hospedadas en Internet o en cualquier otra red.
Colaborar con otras personas implica gestionar estos repositorios remotos enviando y trayendo datos de ellos cada vez que necesites compartir tu trabajo. Gestionar repositorios remotos incluye saber cómo añadir un repositorio remoto, eliminar los remotos que ya no son válidos, gestionar varias ramas remotas, definir si deben rastrearse o no y más.
Ver los remotos
Para ver los remotos que tienes configurados, debes ejecutar el comando
git remote
Si has clonado tu repositorio, deberías ver al menos origin (origen, en inglés) - este es el nombre que por defecto Git le da al servidor del que has clonado:
❯ git clone https://github.com/progit/progit2
Cloning into 'progit2'...
remote: Enumerating objects: 16983, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 16983 (delta 0), reused 0 (delta 0), pack-reused 16979 (from 1)
Receiving objects: 100% (16983/16983), 182.59 MiB | 13.91 MiB/s, done.
Resolving deltas: 100% (10458/10458), done.
❯ cd progit2
~/progit2 main ❯ git remote
origin
También puedes pasar la opción -v, la cual muestra las URLs que Git ha asociado al nombre y que serán usadas al leer y escribir en ese remoto:
~/progit2 main ❯ git remote -v
origin https://github.com/progit/progit2 (fetch)
origin https://github.com/progit/progit2 (push)
Añadir remotos
Para añadir un remoto nuevo y asociarlo a un nombre que puedas referenciar fácilmente, ejecuta:
git remote add [nombre] [url]:
por ejemplo:
~/progit2 main ❯ git remote add other_repo https://codeberg.org/maria/progit2
~/progit2 main ❯ git remote -v
origin https://github.com/progit/progit2 (fetch)
origin https://github.com/progit/progit2 (push)
other_repo https://codeberg.org/maria/progit2 (fetch)
other_repo https://codeberg.org/maria/progit2 (push)
Traer remotos
A partir de ahora puedes usar el nombre maria en la línea de comandos en lugar de la URL entera. Por ejemplo, si quieres traer toda la información que tiene maria pero tú aún no tienes en tu repositorio, puedes ejecutar:
git fetch maria
El comando irá al proyecto remoto y se traerá todos los datos que aun no tienes de dicho remoto. Luego de hacer esto, tendrás referencias a todas las ramas del remoto, las cuales puedes combinar e inspeccionar cuando quieras.
Es importante destacar que el comando git fetch solo trae datos a tu repositorio local - ni lo combina automáticamente con tu trabajo ni modifica el trabajo que llevas hecho. La combinación con tu trabajo debes hacerla manualmente cuando estés listo.
Si has configurado una rama para que rastree una rama remota, puedes usar el comando git pull para traer y combinar automáticamente la rama remota con tu rama actual.
Los remotos pueden estar en cualquier ordenador, github, gitlab, sourcehut o codeberg, son sólo servicios que nos ofrecen hospedaje para nuestros repositorios. Sin embargo podemos hospedar nuestros repositorios en nuestro propio ordenador, o en cualquier otro(s) donde tengamos acceso ssh.
Además es posible utilizar software como forgejo o cgit (entre muchos otros) para configurar nuestro propio servicio de hosting, por ejemplo en una Raspberry Pi.
Enviar remotos
Cuando tienes un proyecto que quieres compartir, debes enviarlo a un servidor. El comando para hacerlo es simple:
git push [nombre-remoto] [nombre-rama]
Si quieres enviar tu rama main a tu servidor origin (recuerda, clonar un repositorio establece esos nombres automáticamente), entonces puedes ejecutar el siguiente comando y se enviarán todos los commits que hayas hecho al servidor:
$ git push origin main
Ramas o branches
Cualquier sistema de control de versiones moderno tiene algún mecanismo para soportar el uso de ramas. Cuando hablamos de ramificaciones, significa que tú has tomado la rama principal de desarrollo (master) y a partir de ahí has continuado trabajando sin seguir la rama principal de desarrollo.
Apuntadores
En cada confirmación de cambios (commit), Git almacena una instantánea de tu trabajo preparado. Dicha instantánea contiene además unos metadatos con el autor y el mensaje explicativo, y uno o varios apuntadores (pointers) a las confirmaciones (commit) que sean padres directos de esta (un padre en los casos de confirmación normal, y múltiples padres en los casos de estar confirmando una fusión (merge) de dos o más ramas).
Una rama Git es simplemente un apuntador móvil apuntando a una de esas confirmaciones. La rama por defecto de Git es la rama master. Con la primera confirmación de cambios que realicemos, se creará esta rama principal master apuntando a dicha confirmación. En cada confirmación de cambios que realicemos, la rama irá avanzando automáticamente.
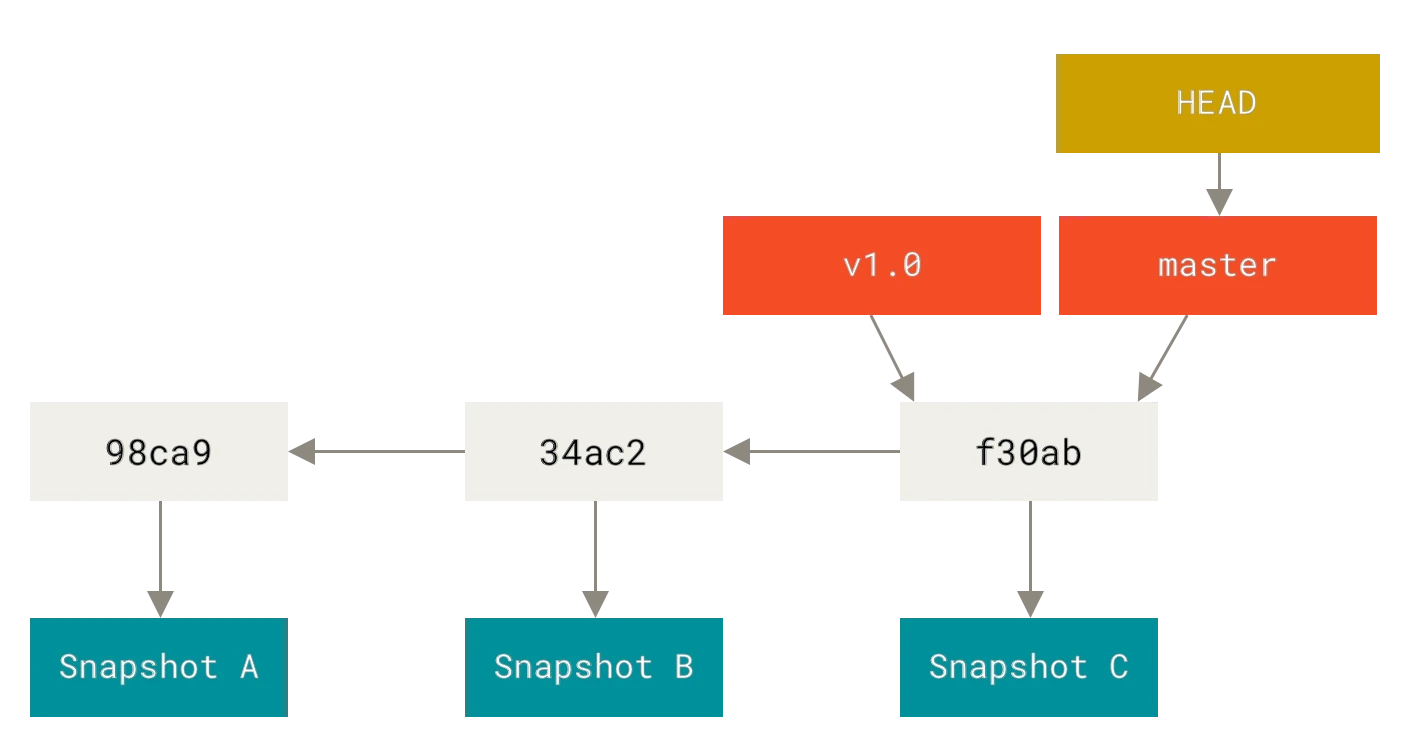
Crear una rama
¿Qué sucede cuando creas una nueva rama? simplemente se crea un nuevo apuntador para que lo puedas mover libremente. Por ejemplo, supongamos que quieres crear una rama nueva denominada "testing". Para ello, usarás el comando git branch:
$ git branch testing
Esto creará un nuevo apuntador apuntando a la misma confirmación donde estés actualmente.
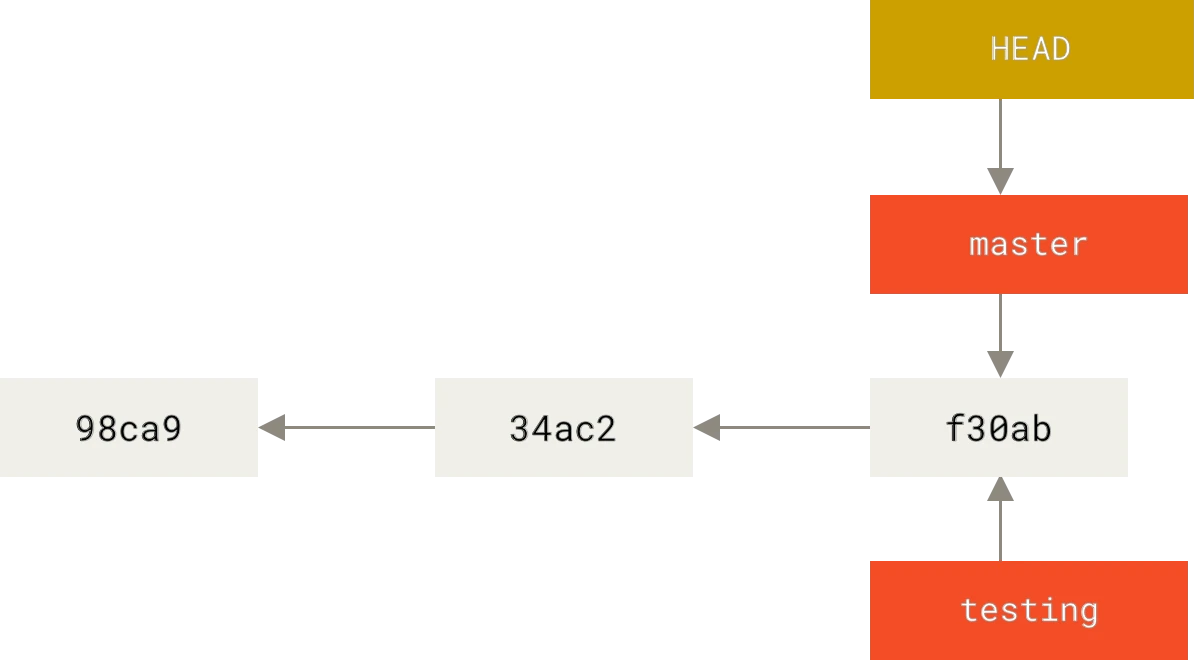
Cambiar de Rama
Para saltar de una rama a otra, tienes que utilizar el comando git checkout. Hagamos una prueba, saltando a la rama testing recién creada:
$ git checkout testing
Esto mueve el apuntador HEAD a la rama testing.
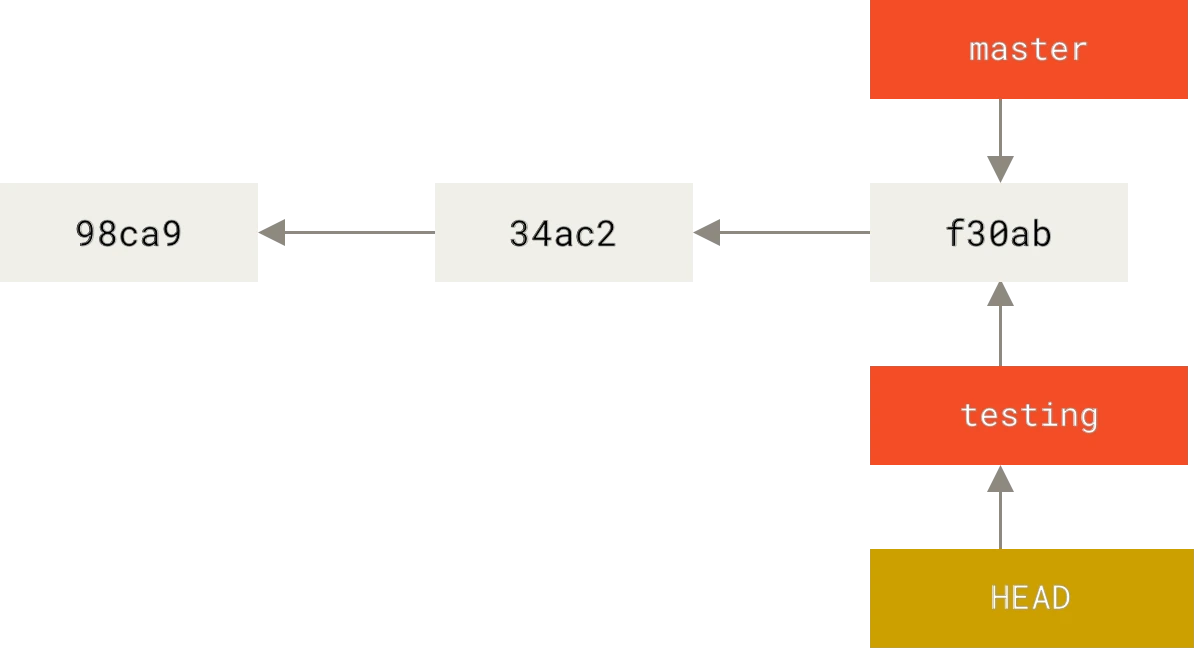
Si ahora hacemos algún cambio y lo confirmamos, la rama apuntada por HEAD avanza con cada confirmación de cambios y vemos que la rama testing avanza, mientras que la rama master permanece en la confirmación donde estaba cuando lanzaste el comando git checkout para saltar a testing.
$ vim test.rb
$ git commit -a -m 'made a change'
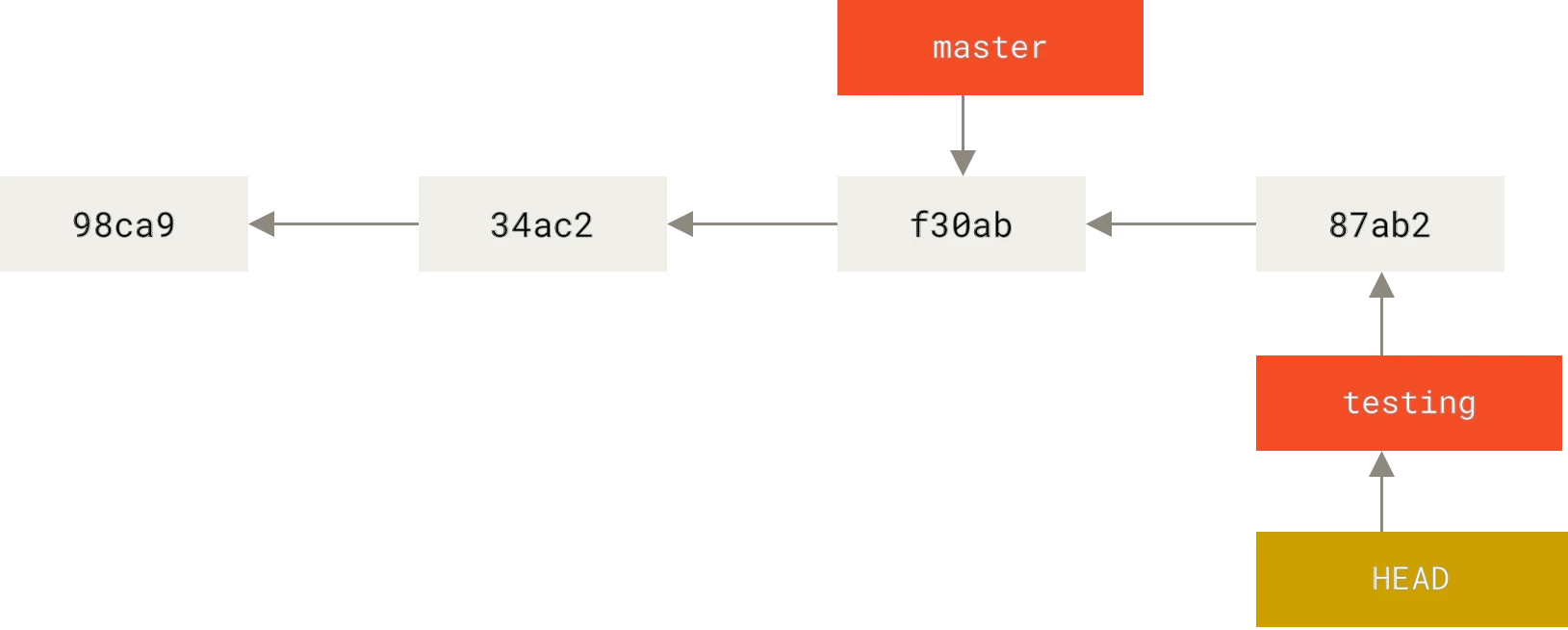
El commando git branch listará todas las ramas disponibles en el repositorio donde nos encontremos.
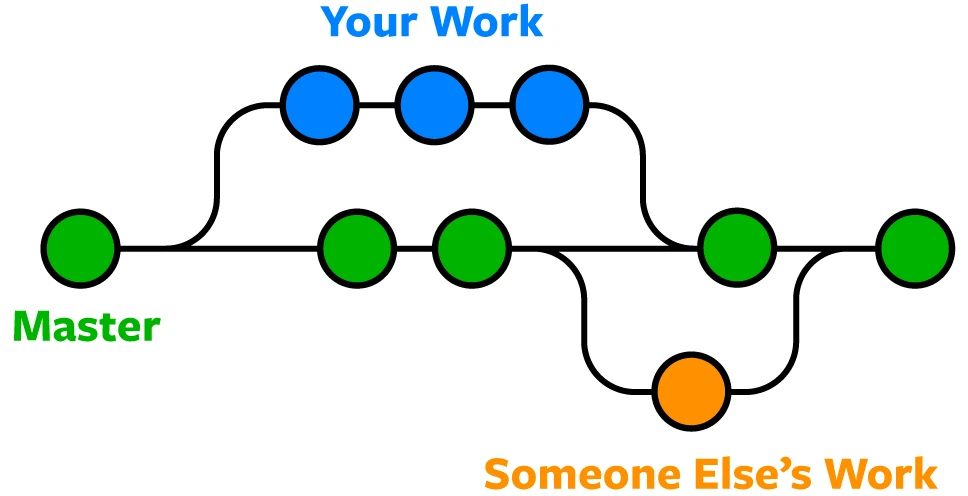
Fusión (merge) de ramas
En este ejemplo tenemos una rama llamada iss53 la cual a partir del commit C2 se desarrolló de forma separada a la rama master.
Debido a que la confirmación en la rama actual (C4) no es ancestro directo de la rama que pretendes fusionar (C5), Git tiene cierto trabajo extra que hacer. Git realizará una fusión a tres bandas, utilizando las dos instantáneas apuntadas por el extremo de cada una de las ramas y por el ancestro común a ambas. Git identifica automáticamente el mejor ancestro común para realizar la fusión de las ramas.
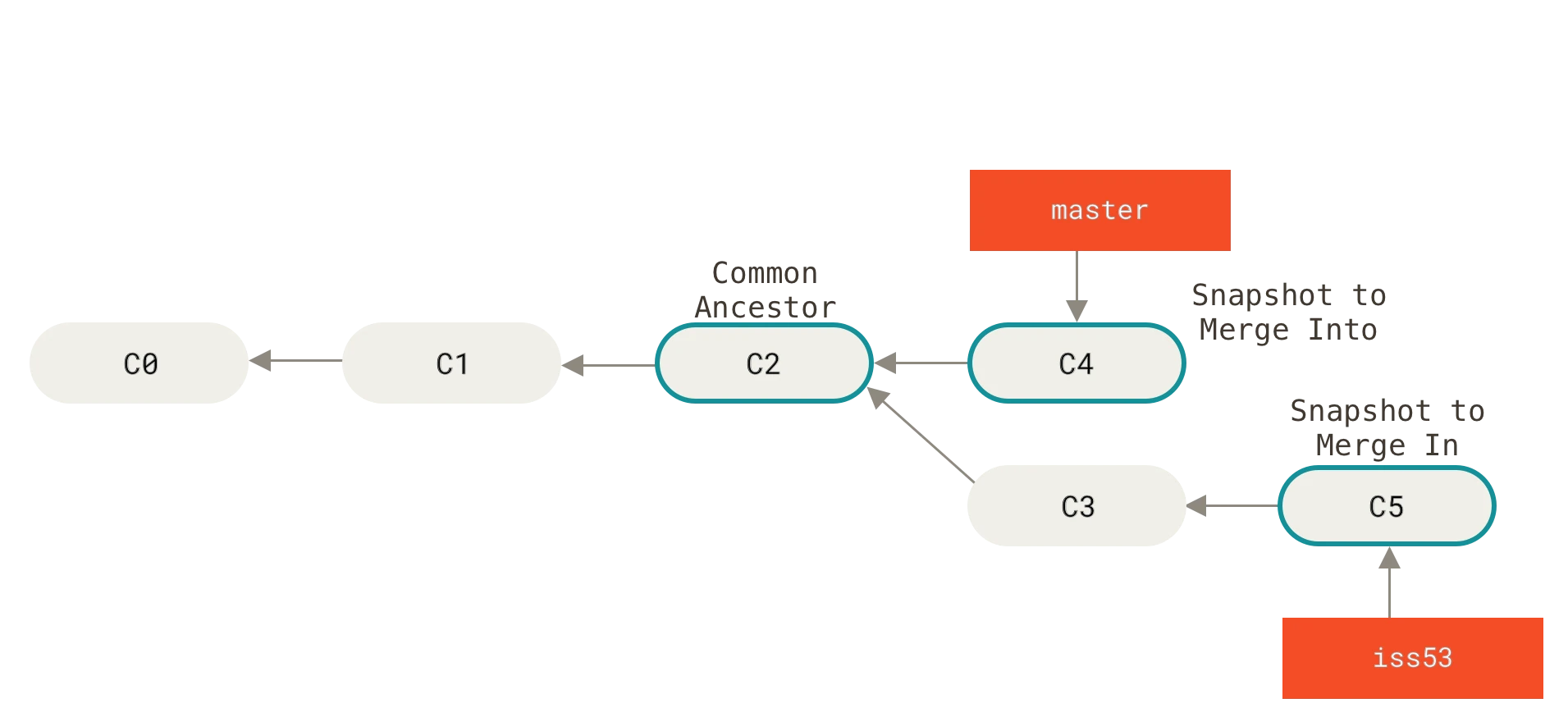
Para fusionar estas ramas saltamos a la rama master y usamos el commando merge para fusionar otra rama con la actual:
$ git checkout master
Switched to branch 'master'
$ git merge iss53
En lugar de simplemente avanzar el apuntador de la rama, Git crea una nueva instantánea (snapshot) resultante de la fusión a tres bandas; y crea automáticamente una nueva confirmación de cambios (commit) que apunta a ella. Nos referimos a este proceso como "fusión confirmada" y su particularidad es que tiene más de un padre.

Manual de git
El libro Pro Git lo puedes encontrar en inglés o en castellano (PDF)
Extensa lista de tutoriales, guías, videos, cursos y libros de todos los niveles.
Gran parte de esta documentación está extraída o basada en el libro Pro Git escrito por Scott Chacon y Ben Straub el cual está bajo la licencia Creative Commons Attribution Non Commercial Share Alike 3.0 license, muchas gracias a los autores y a todos los que han contribuido en esa obra.
Books

📚 Pro Git
A Complete Introduction Scott Chacon and Ben Straub, 2009
Pro Git is your fully-updated guide to Git and its usage in the modern world. Git has come a long way since it was first developed by Linus Torvalds for Linux kernel development. It has taken the open source world by storm since its inception in 2005, and this book teaches you how to use it like a pro.
You can find the full book in pdf or epub, and a spanish version on pdf or epub.